なぜ今「Dify」でチャットボットなのか
社内への問い合わせ対応やドキュメント探しを効率化したい ── そう考えたとき、真っ先に候補に挙がるのがチャットボットです。しかし、従来型のボットは Q&A パターンを一つひとつ登録したり、複雑なシナリオ分岐を管理したりと、構築・運用のコストが馬鹿になりませんでした。
そこで注目されているのが Dify のような LLM プラットフォームです。
Dify が選ばれる理由は、主に以下の点にあります。
- プロンプトとデータで制御: 大量のシナリオを書かなくても、指示(プロンプト)と資料(ナレッジ)があればそれらしい挙動を作れる
- 視覚的なフロー構築: Chatflow 機能により、処理の流れを画面上でつなぎ合わせるだけで実装できる
- 統合の容易さ: Web サイトへの埋め込みや外部ツール連携が標準で用意されている
本記事では、高度な自動化や複雑なチューニングは一旦脇に置き、「まずは動く社内向けチャットボットを 1 つ作る」までの手順を整理します。
そもそも Dify とは何か
そもそも Dify とはどのようなサービスなのかを簡単に整理しておきます。
Dify は、大規模言語モデル(LLM)を利用したアプリケーションを構築・運用するための LLM アプリ開発プラットフォームです。Web 上の管理画面から操作でき、次のようなことをまとめて扱えるようになっています。
- 利用する LLM や埋め込みモデル(OpenAI や Azure OpenAI など)の管理
- チャットボットやエージェントなど「アプリケーション」の作成
- PDF やテキストを登録して検索できる「ナレッジベース」の管理
- ノードをつないで処理の流れを組み立てる「フロー(Chatflow)」の設計
- 作成したボットを Web ウィジェットや API 経由で外部から利用するための設定
従来であれば、自分たちでバックエンドを用意し、LLM の API を呼び出すコードや、ナレッジ検索の仕組みを実装する必要がありました。Dify は、そのあたりの共通部分をプラットフォームとしてまとめて提供してくれるため、
- サーバーやフレームワークの細かな設定をあまり意識せずに
- 「どのような質問に、どのように答えてほしいか」という 振る舞いの設計に集中して
チャットボットや RAG アプリケーションを作成できるのが特徴です。
また、Dify には大きく分けて次の 2 つの提供形態があります。
- クラウド版(SaaS 版)
公式サイトでアカウントを作成するだけで利用を開始できる形態です。インフラの準備やアップデートは Dify 側で行われるため、「まず試してみたい」「少人数で素早く検証したい」といったケースに向いています。 - セルフホスト版(オンプレミス/自社クラウド版)
オープンソースとして公開されている Dify を、自社サーバーやクラウド環境にインストールして利用する形態です。インフラの管理やアップデートは自分たちで行う必要がありますが、データの所在を自社の管理下に置きたい場合や、細かなカスタマイズを行いたい場合に適しています。
本コラムで扱っている「社内向けチャットボット」の例では、どちらの形態でも基本的な考え方は同じです。クラウド版であってもセルフホスト版であっても、
- LLM や埋め込みモデルの設定
- 社内ドキュメントを登録するナレッジベース
- 質問を受け取り、ナレッジを検索し、その結果をもとに回答を生成するフロー(Chatflow)
といった要素を Dify 上で組み合わせていく、という構造は変わりません。
このように、Dify は「LLM を使ったアプリケーションの部品」をひととおり揃えてくれる土台として利用できる、というイメージを持っていただくと理解しやすいと思います。
参照:Dify
今回つくるチャットボットの全体像
想定するユースケースは、以下のようなシンプルな社内ボットです。
- 対象: 社員(総務・情シスへの問い合わせなど)
- 目的: 規程やマニュアルなど、ドキュメントを見ればわかる質問への一次回答
- 参照データ: 社内 Wiki、PDF マニュアル、手順書のテキストなど
Dify 上の構成は次のようになります。
- LLM: OpenAI / Azure OpenAI などのモデル
- ナレッジベース: 社内ドキュメントの保管場所
- アプリケーション: Chatflow で作成するボット本体
- フロントエンド: 社内ポータル等に埋め込む Web ウィジェット
Dify の準備:ワークスペースとプロバイダ設定
まずは Dify を利用するための下準備です。
アカウント作成とワークスペース
Dify の利用にはアカウントが必要です。クラウド版を利用する場合は公式サイトから登録し、ログインします。
 ログイン後の状態です。
ログイン後の状態です。
LLM プロバイダの設定
Dify 自体は LLM を持っていないため、外部のモデルを利用する設定が必要です。OpenAI や Azure OpenAI Service など、利用可能な API キーを用意してください。
手順はシンプルです。
- Dify 画面右上のアイコンから「設定」を開く
- 設定メニューから「モデルプロバイダー」を開く ⇒ 利用するプロバイダ(例:OpenAI)をインストール
- API キーを入力して保存
設定を開きます
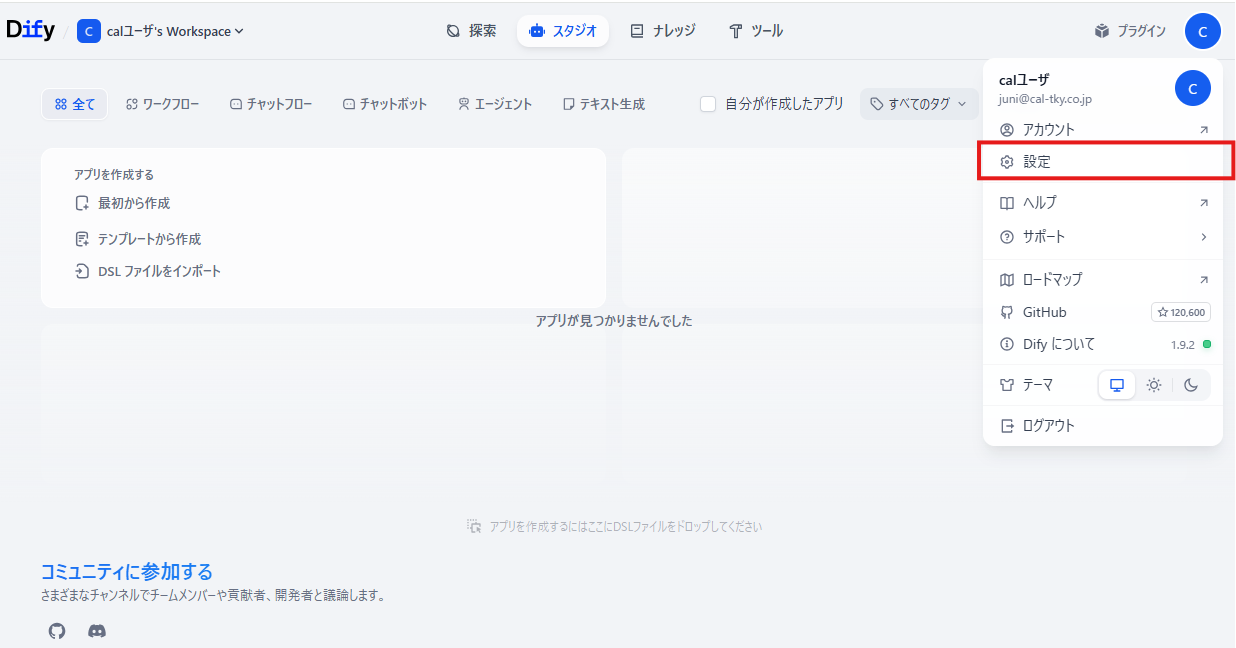
利用するプロバイダをインストールします。今回は gpt モデルを使いたいため Open AI をインストールします。
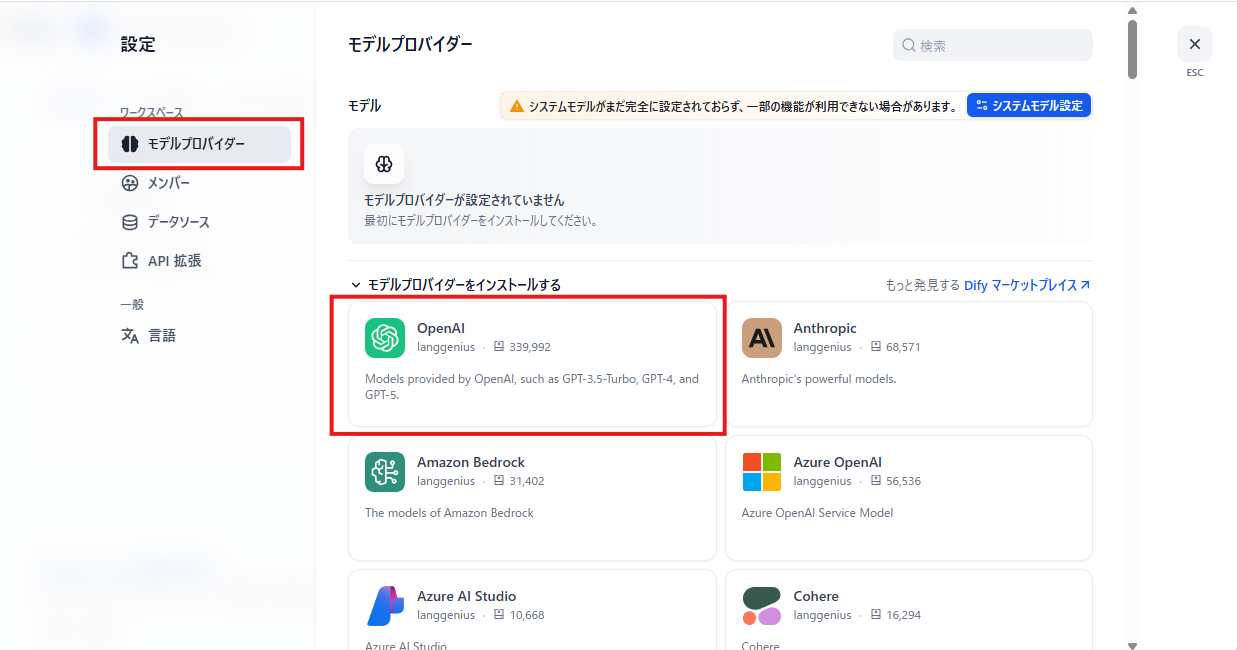
インストールが完了するとセットアップメニューが表示されます。
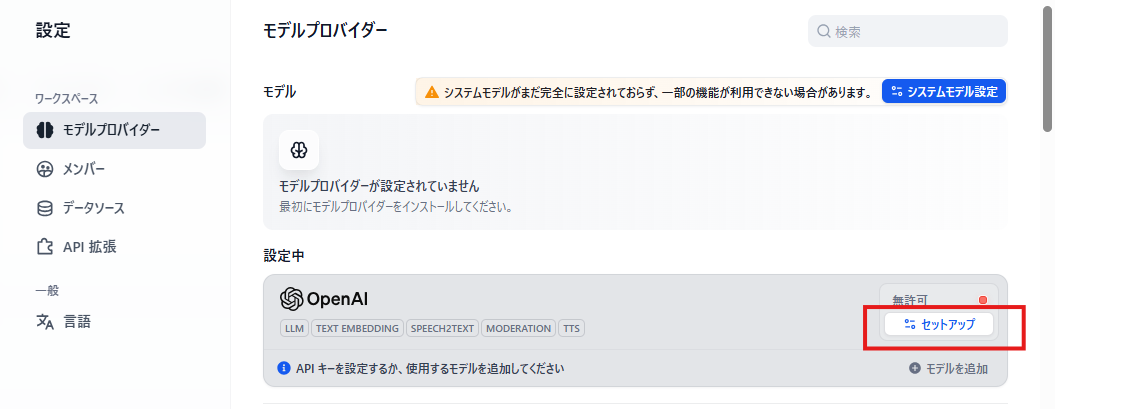
事前にOPEN AIにて取得した API KEY をセットします。API KEY 以外の項目は任意項目です。
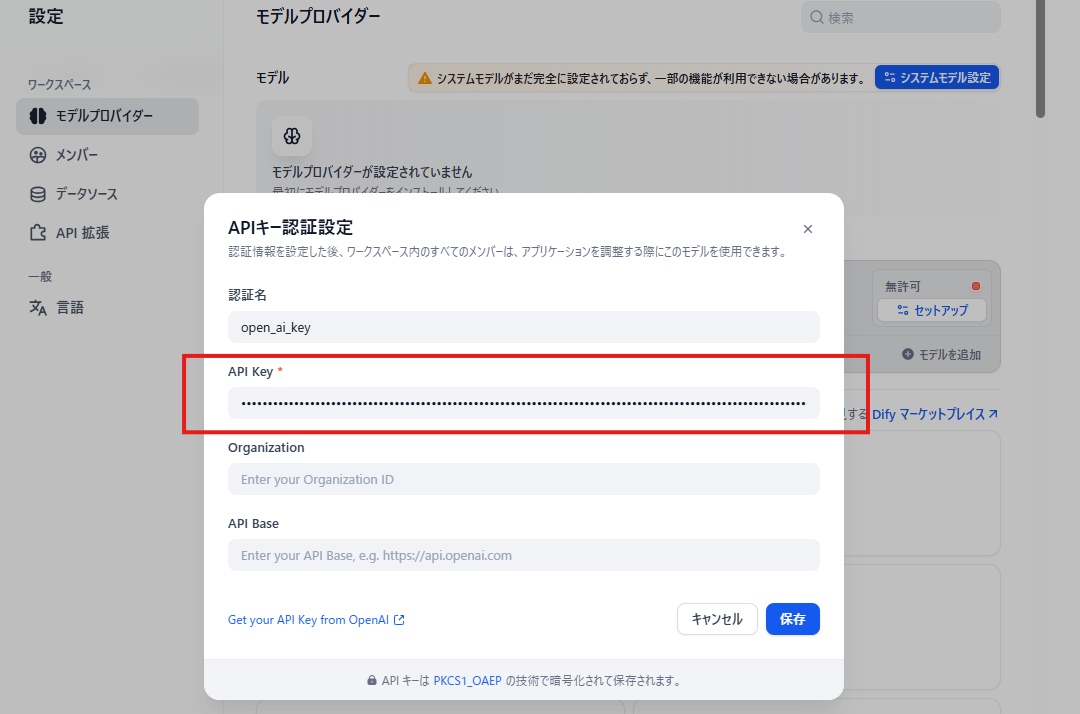
グリーンになれば設定完了です。以降、モデルの選択を行う場面では設定したモデルプロバイダーが提供している LLM モデルが利用可能となります。
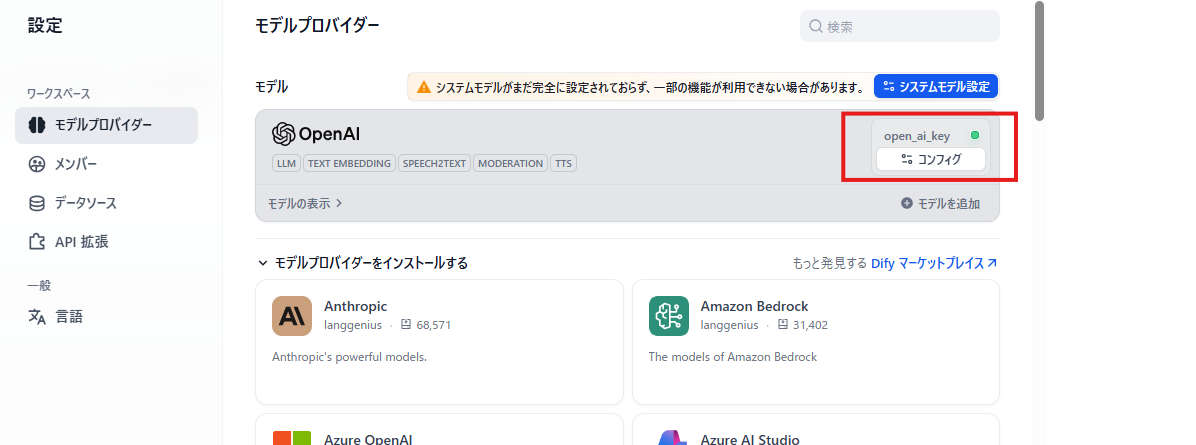
ナレッジベースの作成:社内ドキュメントを登録する
LLM は一般的な知識は持っていますが、当然ながら「自社の就業規則」や「独自ツールの使い方」は知りません。そこで、Dify の「ナレッジベース」機能を使って社内ドキュメントを読み込ませます。
登録できるデータ
Dify は以下の形式に対応しています。
- PDF(マニュアル、規程集など)
- Web ページ(Notion や Wiki などの URL)
- テキストファイル / Markdown
- Excel / Word など
ナレッジを開きます

ナレッジベースを開きます
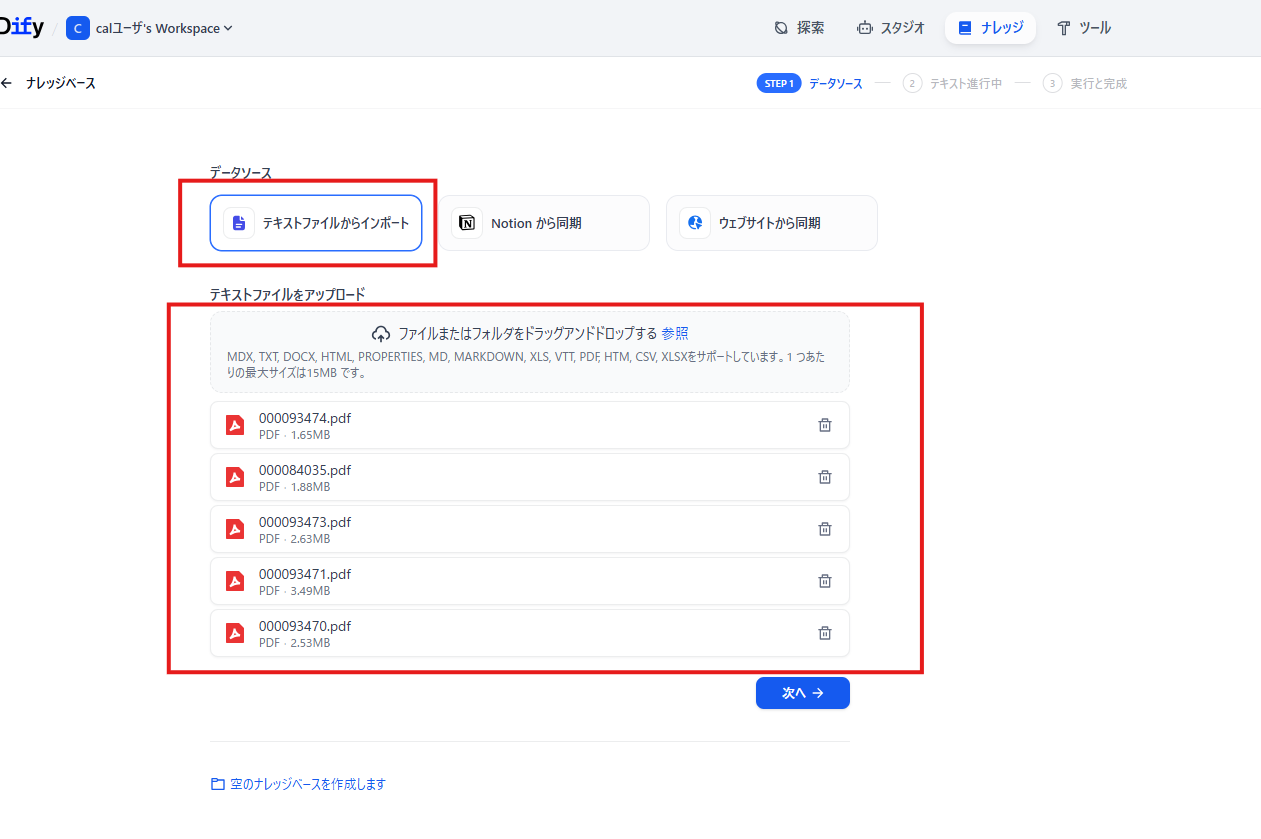
データソースを選択します。
今回は IPA が発行している「中小規模製造業者の製造分野におけるデジタルトランスフォーメーション(DX)推進のためのガイド」のページリンクで公開されている各種 PDF をナレッジとして登録してみます。「テキストファイルからインポート」を選択し、PDF をドラッグ&ドロップします。
完了したら「次へ」を押すのですが、ドロップしたファイルが多すぎると「次へ」ボタンが非活性のままになるので注意してください。
続いて RAG の設定になります。
今回は細かいことは気にしないのでデフォルトのまま進めますが、チャンク長や検索方法の設定により RAG の精度が変わります。
設定中ほどの埋め込みモデルには、先ほど設定したモデルプロバイダーで利用できる**埋め込みモデル(後述)**が設定されているはずです。
画面下部の「保存して処理」を押下してください。
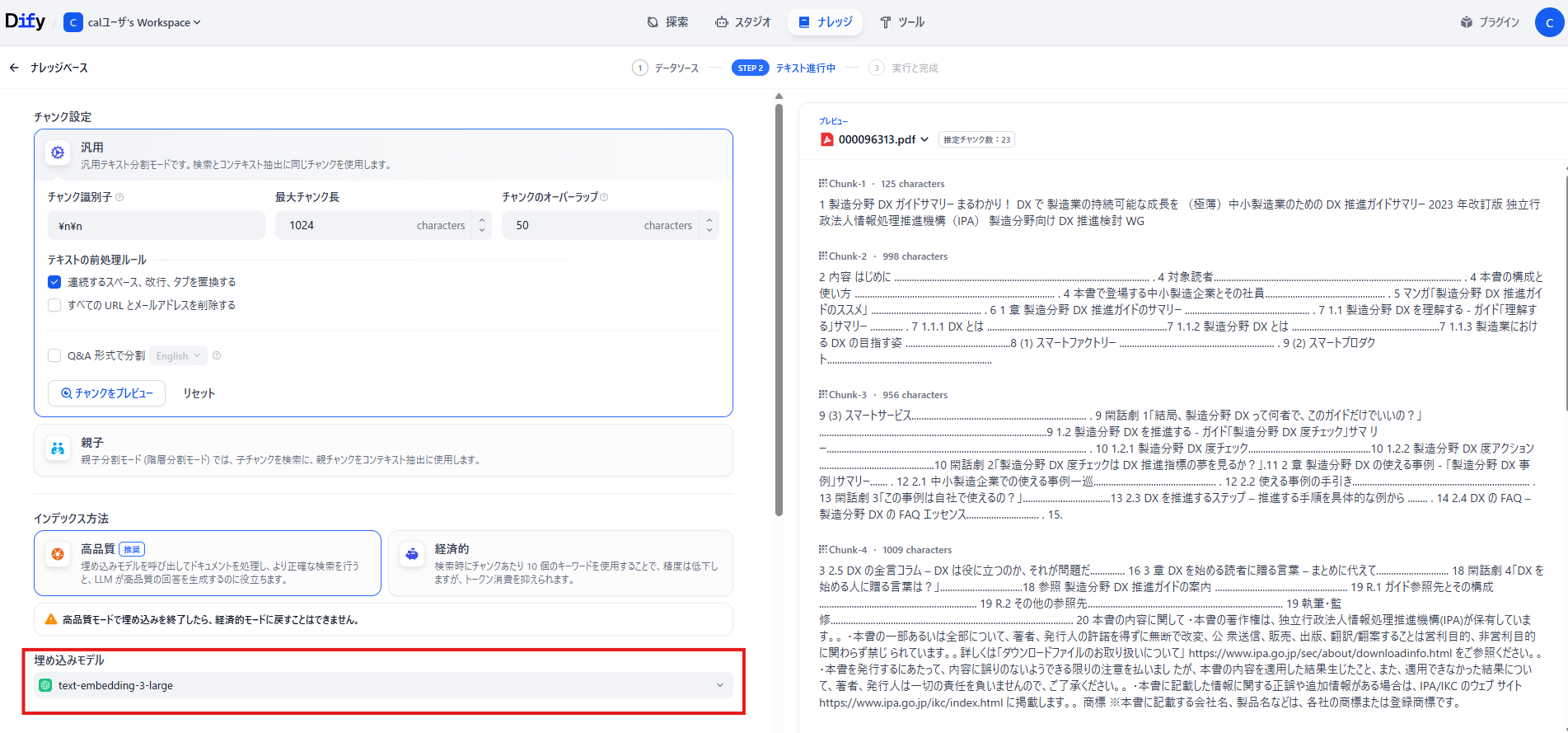
しばらくするとナレッジの登録処理が完了します。
埋め込みモデル(Embedding Model)について
ナレッジベースを作成する際、「埋め込みモデル」の選択を求められます。 これは文章を数値ベクトルに変換し、意味の近さを計算できるようにするためのモデルです。これを通すことで、キーワードが完全に一致しなくても、意味的に近いドキュメントを探し出せるようになります。
基本的には Dify が推奨するモデル(OpenAI の text-embedding-3-small など)を選んでおけば問題ありませんが、以下の点は意識しておくと良いでしょう。
- 日本語と英語が混在する場合は、多言語対応のモデルを選ぶ
- 後からモデルを変更する場合は、ナレッジの再取り込み(再インデックス)が必要になる
いわゆる「RAG」の構成
ここまでの手順は、技術用語でいう RAG(Retrieval-Augmented Generation) の構築にあたります。
- Retrieval(検索): ユーザーの質問に近い情報をナレッジベースから探す
- Generation(生成): 見つかった情報と質問をセットにして LLM に渡し、回答を書かせる
Dify では、この複雑な処理を「ナレッジベース」と「Chatflow」の組み合わせだけで実現できます。
まずは、範囲を絞って試すことをおすすめします。「全社のあらゆるドキュメント」を入れると管理が難しくなるため、最初は「総務のよくある質問集」や「特定のプロジェクト資料」など、特定の業務領域に限定したナレッジベースを作成するのがコツです。
Chatflow でボットの挙動を設計する
データが用意できたので、チャットボットを作成していきます。
アプリケーションの作成
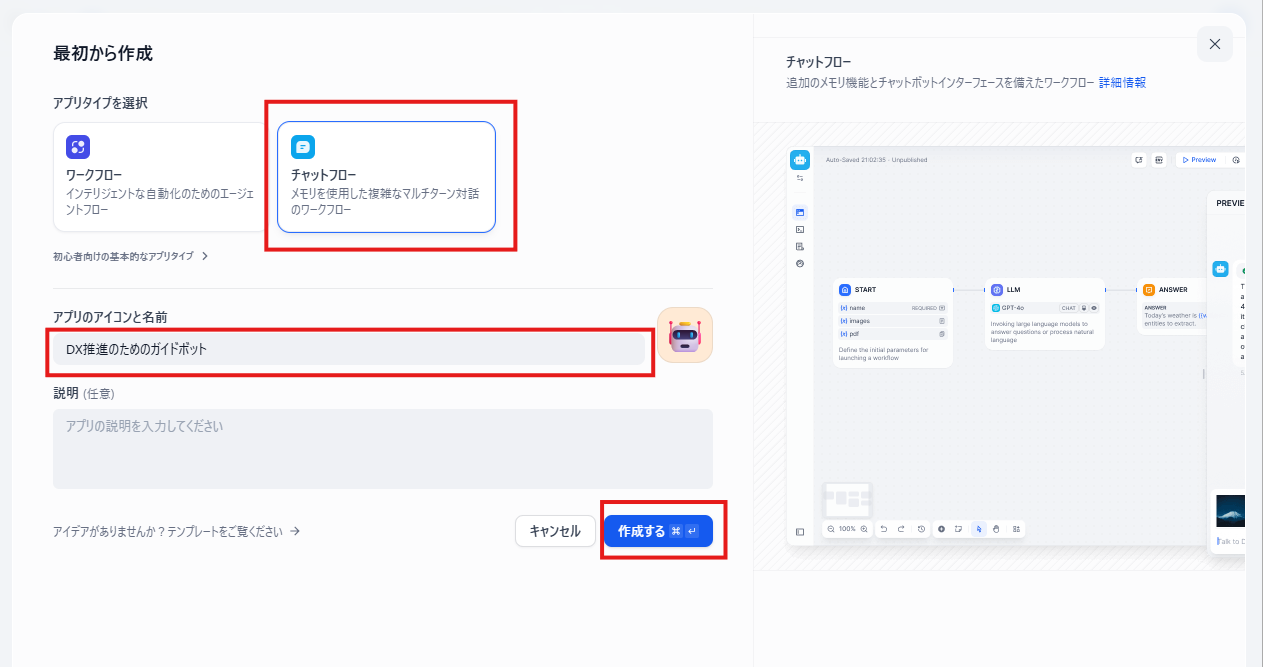
「最初から作成」ボタンを押し、アプリのタイプで**「チャットフロー」**を選択します。「アプリのアイコンと名前」はチャットボットの名称となりますので任意の値を入力してください。

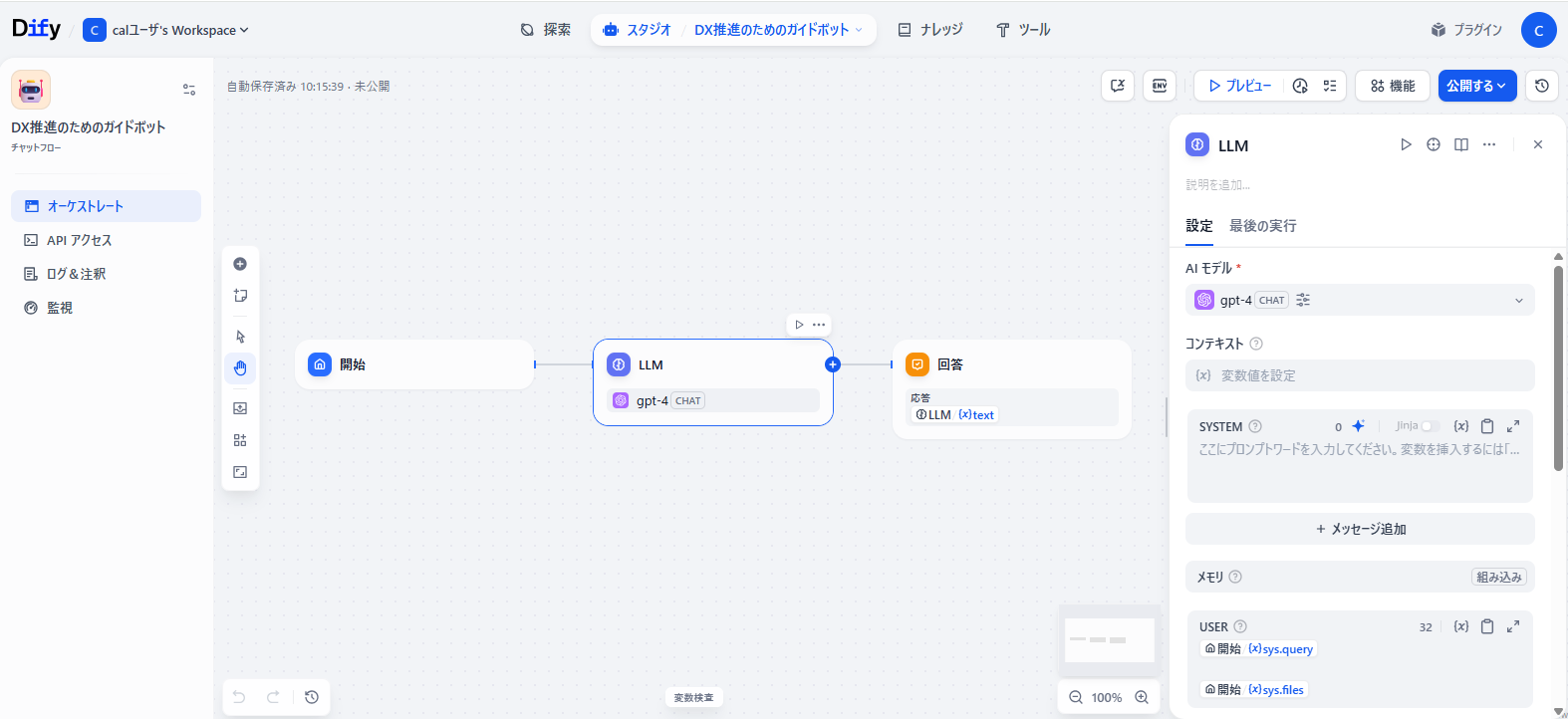
エディタ画面が開くと、「開始」⇒「LLM」⇒「回答」という3つのブロックからなるフローが作成されます。
各ブロックには以下の役割をもっています。
- 開始: ユーザーからの入力を受け取る
- LLM: 検索結果をもとに回答を生成する
- 回答: ユーザーへメッセージを返す
知識検索ブロックの設定
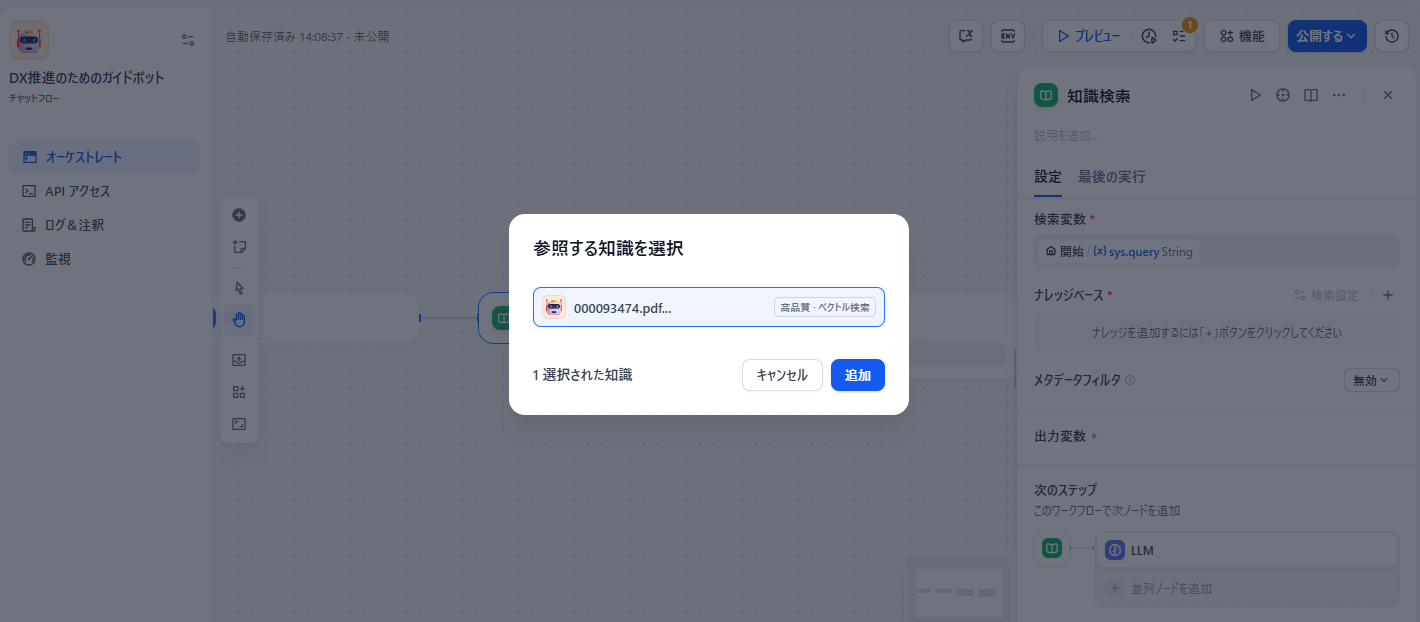
このフローに先ほど作成したナレッジベースを紐づけます。
「開始」と「LLM」を結ぶ線をクリックし、**「知識検索」**ブロックを追加します
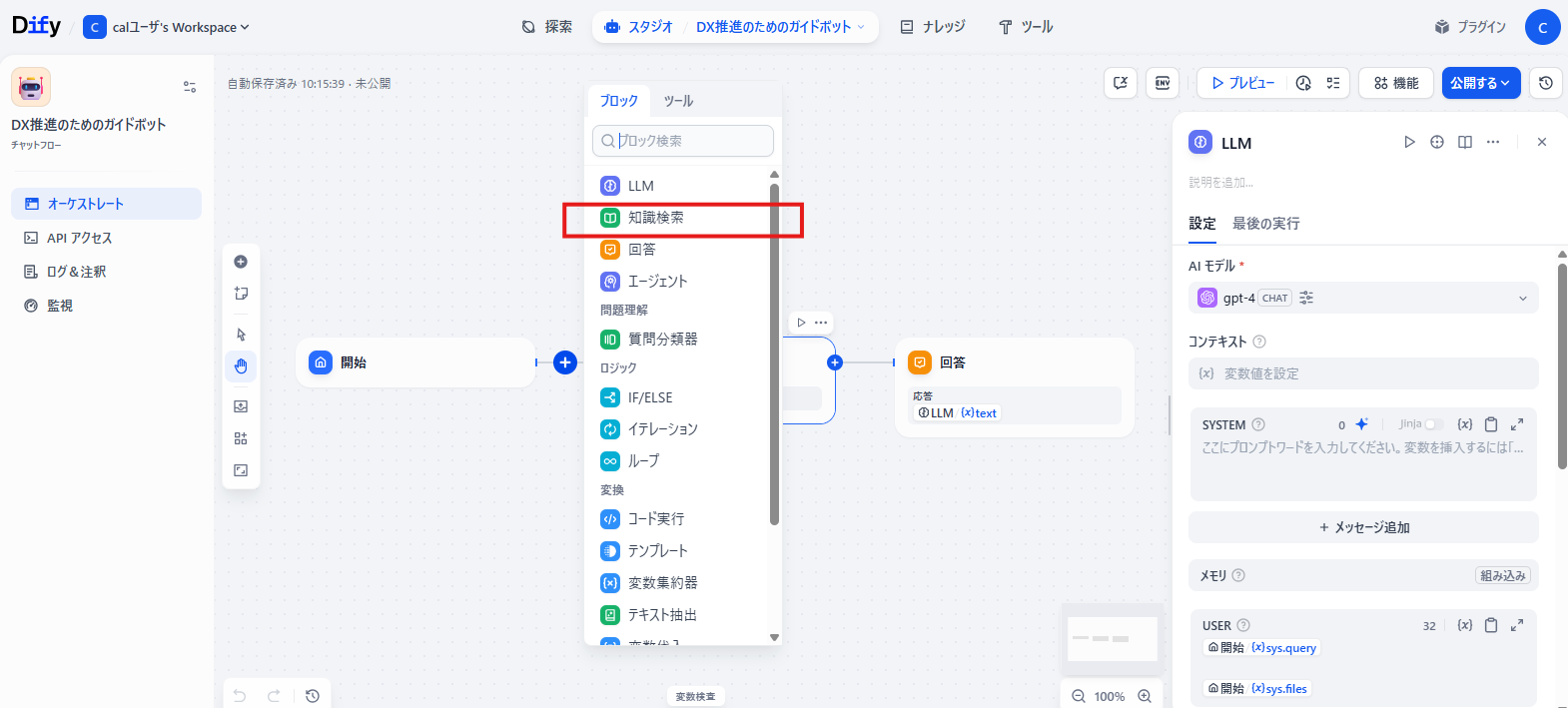
追加した **「知識検索」**ブロックを選択すると、画面右側にプロパティ設定パネルが表示されます。
「ナレッジベース」という項目に、先ほど作成したナレッジベースを紐づけてください

LLM ブロックの設定
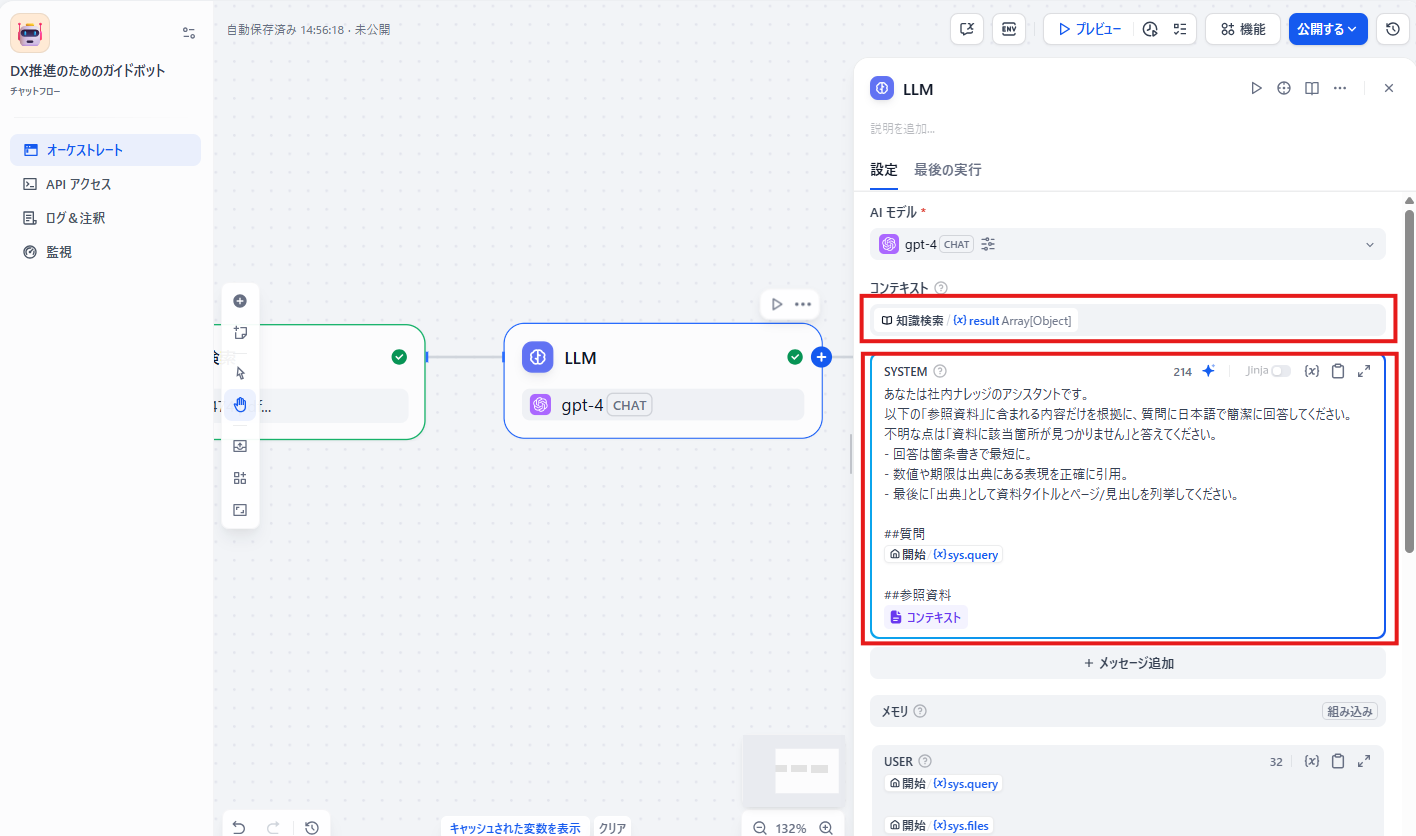
LLM を選択し、知識検索ブロックの結果から回答生成するように各種設定を行います。
- コンテキスト: (知識検索の)result
- system:LLM に命令プロンプトをセットします。例えば以下のような設定を記載します。
あなたはDX推進アシスタントです。
以下の「参照資料」に含まれる内容だけを根拠に、質問に日本語で簡潔に回答してください。
不明な点は「資料に該当箇所が見つかりません」と答えてください。
- 回答は箇条書きで最短に。
- 数値や期限は出典にある表現を正確に引用。
- 最後に「出典」として資料タイトルとページ/見出しを列挙してください。
【質問】
sys.query
【参照資料(抜粋)】
コンテキスト
このように**「何に基づいて答えるか」「分からないときはどうするか」**を明記することで、AI 特有の「もっともらしい嘘(ハルシネーション)」を抑制できます。
動かしてみる
作成したチャットボットを動かしてみましょう
「公開する」⇒「更新を公開」⇒「アプリを実行」を押下してください。

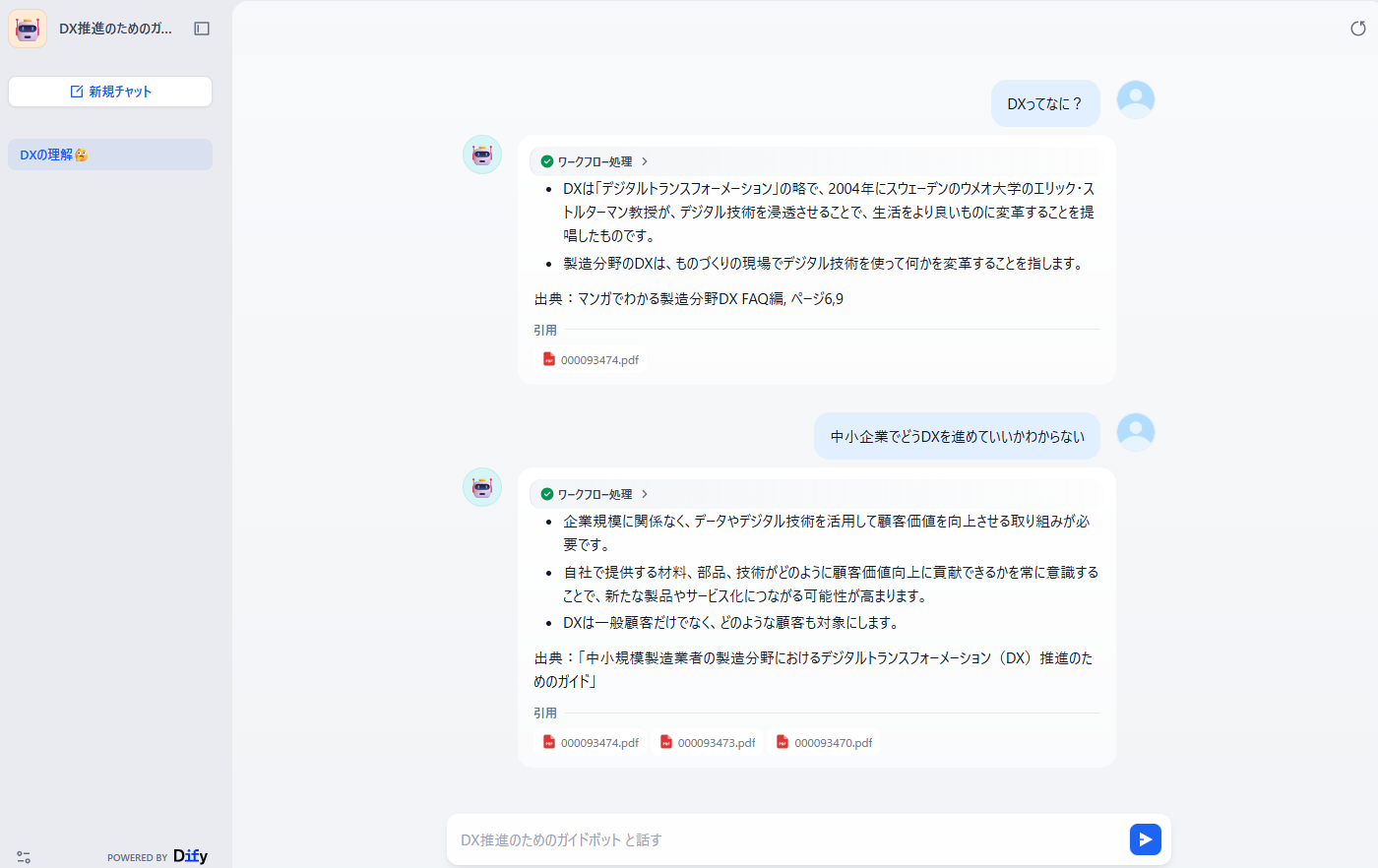
チャット画面が立ち上がるので、ナレッジに関する質問を投げてみましょう。
どの資料を参考にしたのかも含めて回答が返ってくることを確認できました。
Web サイトや社内ツールへの組み込み
動作確認ができたら、実際の利用環境へ展開します。Dify は標準で埋め込み用のコードを発行してくれます。
Web ウィジェットの利用
- アプリ画面の「公開する」または「監視」セクションにある**「埋め込み」**メニューを開きます。
- 表示されたスクリプトタグをコピーします。
- 社内ポータルやイントラネットの HTML(
<body>タグ内など)に貼り付けます。
これだけで、画面の右下にチャットアイコンが表示され、作成したボットと会話ができるようになります。
Slack や Teams 連携
チャットツールへの連携も可能です。Dify 側では API や Webhook が用意されているため、Slack App などを経由してボットを呼び出すことができます。 日常的に使うツールに組み込むことで、わざわざ別画面を開く手間が減り、利用率の向上が期待できます。
運用時に意識したいポイント
最後に、実際に運用してみて分かった設計のコツをいくつか共有します。
FAQ に向くもの、向かないもの
Dify の RAG チャットボットが得意なのは、「ドキュメントはあるが探すのが面倒なもの」や「表記揺れが多くキーワード検索でヒットしにくいもの」です。
一方で、以下のようなケースは慎重になる必要があります。
- 最新の正確性が必須なもの: 給与計算や法務関連など、少しの誤りも許されない領域
- 今日変わったばかりの情報: ナレッジの更新(再インデックス)が追いついていないと古い回答をしてしまう
重要な判断が必要な業務については、「あくまで一次回答の参考レベル」として利用するよう、ユーザーに周知しておくのが無難です。
ログを活用して育てる
Dify の管理画面には「ログ」機能があります。ユーザーがどんな質問をして、ボットがどう答えたか(どのドキュメントを参照したか)を確認できます。
- 答えられなかった質問を見つけ、ナレッジに追加する
- 誤った回答をしていた場合、プロンプトで制約を強める
最初から完璧なボットを作るのは困難です。まずは小さくリリースし、このログを見ながら **「育てていく」**スタンスで運用することをおすすめします。
まとめ
Dify を使うことで、これまでハードルが高かった LLM ベースのチャットボット構築が、驚くほど手軽になります。
- ワークスペースとモデルを設定する
- 社内ドキュメントをナレッジとして登録する
- Chatflow でデータの流れをつなぐ
- Web ウィジェットで公開する
まずは「特定のツールのヘルプ対応」など、範囲を限定した小さなユースケースから始めてみてはいかがでしょうか。実際の業務データで AI が動く様子を見ると、次の活用アイデアもきっと浮かんでくるはずです。